홈 서버를 완전히 잃어버릴 뻔했습니다
2025년 3월 4일
경고: 이 페이지가 작성된지 365일 이상이 경과하였습니다. 해당 내용이 현재와 상이할 수 있습니다.
1월 첫 주 정도에 한국에 있는 가족에게 인사를 하고 유학을 계속 진행하려 다시 미국으로 돌아왔습니다. 별 탈 없이 항공편으로 돌아왔는데, 비행 중에는 폰에 받아둔 영화 몇 편과 스팀덱 게임으로 시간을 보냈습니다. 그래도 항공기가 많이 흔들려서 잠도 잘 못자고, 노이즈켄슬링 헤드셋을 껴도 엔진 소리를 완전히 차단하지 못하니 긴 여정들은 그래도 별로 좋아하기 힘든 듯 합니다.
기체가 착륙 후 게이트로 이동하는 사이, 폰에 비행기 모드를 해제하고 인터넷에 연결하면서 13시간 동안 밀려있던 알림들이 한꺼번에 들어오는 걸 구경했습니다. 그렇게 중요한 건 없는 것 같아, 가방을 들고 다른 분들과 비행기에서 내렸습니다.
비자 체크를 마치고 체크인 가방을 찾은 후 버스들이 모여있는 정류장으로 이동했습니다. 정류장으로 연결해주는 열차를 기다리는 중, 휴대폰에 갑자기 Pushover 알림이 하나 도착합니다. 알림 소리가 중요한 알림에만 울리게 해둬서 별 좋은 얘긴 아닌 줄 직감했죠.
역시, 13시간 동안 고통스런 비행 다 견뎌놓고 다음과 같은 광경을 보게 됩니다:
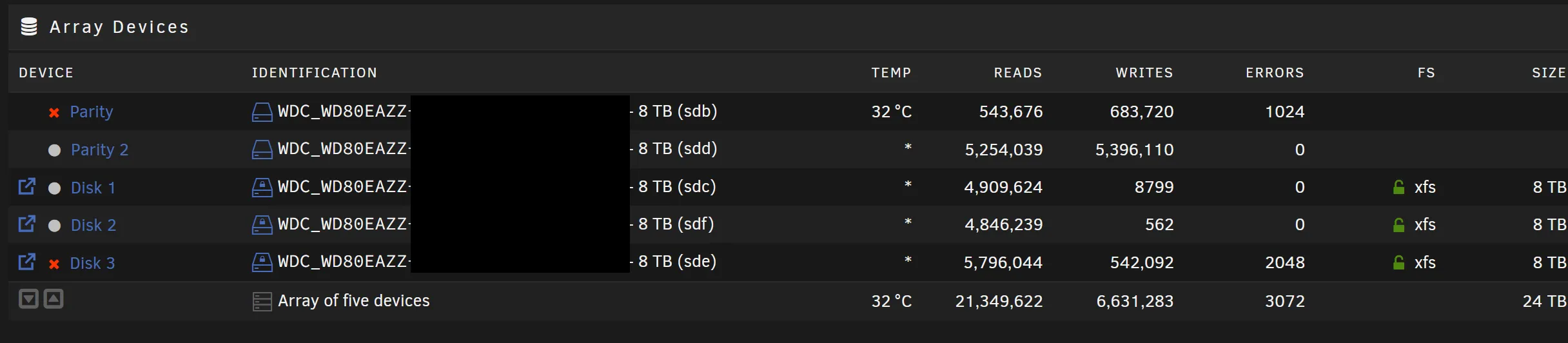
처음 든 생각은: 왜 미국까지 온 다음에야 이런 일이 일어나?! 정답: 머피의 법칙. 두 번째 생각은: 듀얼 패리티로 해두기 잘했다. 처음 디스크 그룹을 설정할 때 낭비라고 생각했는데, 완전히 데이터를 날리기 직전까지 가보니 그런 생각이 전부 사라지더라고요.
한꺼번에 디스크 2개가 고장났다는 점이 수상하게 여겨졌지만, 당시에는 크게 생각하지 않았습니다. (사망플래그.) 묶음 안에 들어간 디스크들은 다른 시기에 구입해서 섞었는데, 한번 구매했을 때 2개를 구매했었는지 잘 기억이 나질 않았거든요. 아마 제조 공정에 문제가 있겠지 했습니다.
어쨌든 16 TB 디스크 2개를 주문해 교체하기로 하고 더 이상의 읽기/쓰기가 나머지 디스크에 무리를 줘서 고장나게 하기 전에 서버 전원을 내려뒀습니다. 그 동안 서버를 사용하지 못하니 가족이 달가워하진 않겠지만, 상황이 악화되서 처음부터 다시 시작하는 것보단 나으니까요.
물론, 최악의 상황에 대처하기 위해 메인 서버에 있는 데이터를 복사해둔 백업 서버가 있긴 있습니다. 하지만, 일석이조로 처리하기 위해 백업 서버 자체는 다른 장소에서 호스팅하고 있어, 백업 스케줄 자체가 매일 모두가 잠든 새벽에만 돌아가고 그마저도 집과의 인터넷 속도 제약을 받고 있죠. 마지막 백업이 언제였냐에 따라 메인 서버에 있는 모든 데이터가 복사되지 않았을 수도 있고, 인터넷으로 거의 18 TB 정도의 데이터를 복원하는 것도 골치아픈 작업이거든요.
그래서 디스크들이 도착한 다음, 가족을 원격으로 도와주며 서버 안에 설치하고, 서버를 킨 다음에 디스크 묶음을 리실버링(resilver)하여 모든 게 순조롭게 마무리되었겠죠?
모든 게 순조롭게 마무리되는 세상
하드 두 개가 도착한 후, 가족과 함께 화상통화로 드라이브를 바꿔끼웠습니다. 이 과정이 살짝 복잡했는데, 메인 서버 케이스로 사용중인 Jonsbo N1은 드라이브를 바꾸기 위해 서버를 메인 케이스 레일을 따라 빼는 것을 요구로 하거든요. 서버 자체도 TV 밑에 미디어 수납장에 있다 보고, 꺼내는 과정에서 실수로 떨어뜨리기라도 한다면 나머지 드라이브들이 죽을 수도 있으니 꺼내면서 조심스레 케이블들을 연결 해제하고 서버 전체를 끄집어내야 됐습니다.
그래도 결국 디스크들을 성공적으로 교체했고, 서버를 부팅시켜 복구 과정을 시작했습니다. 프리클리어(디스크 사용 전 전부 지운 후 디스크가 정상적으로 작동하는지 검증하는 과정)도 그냥 건너뛰었는데, 새로운 디스크들이 불량일 수가 없겠죠?
새로운 디스크들이… 불량입니다?
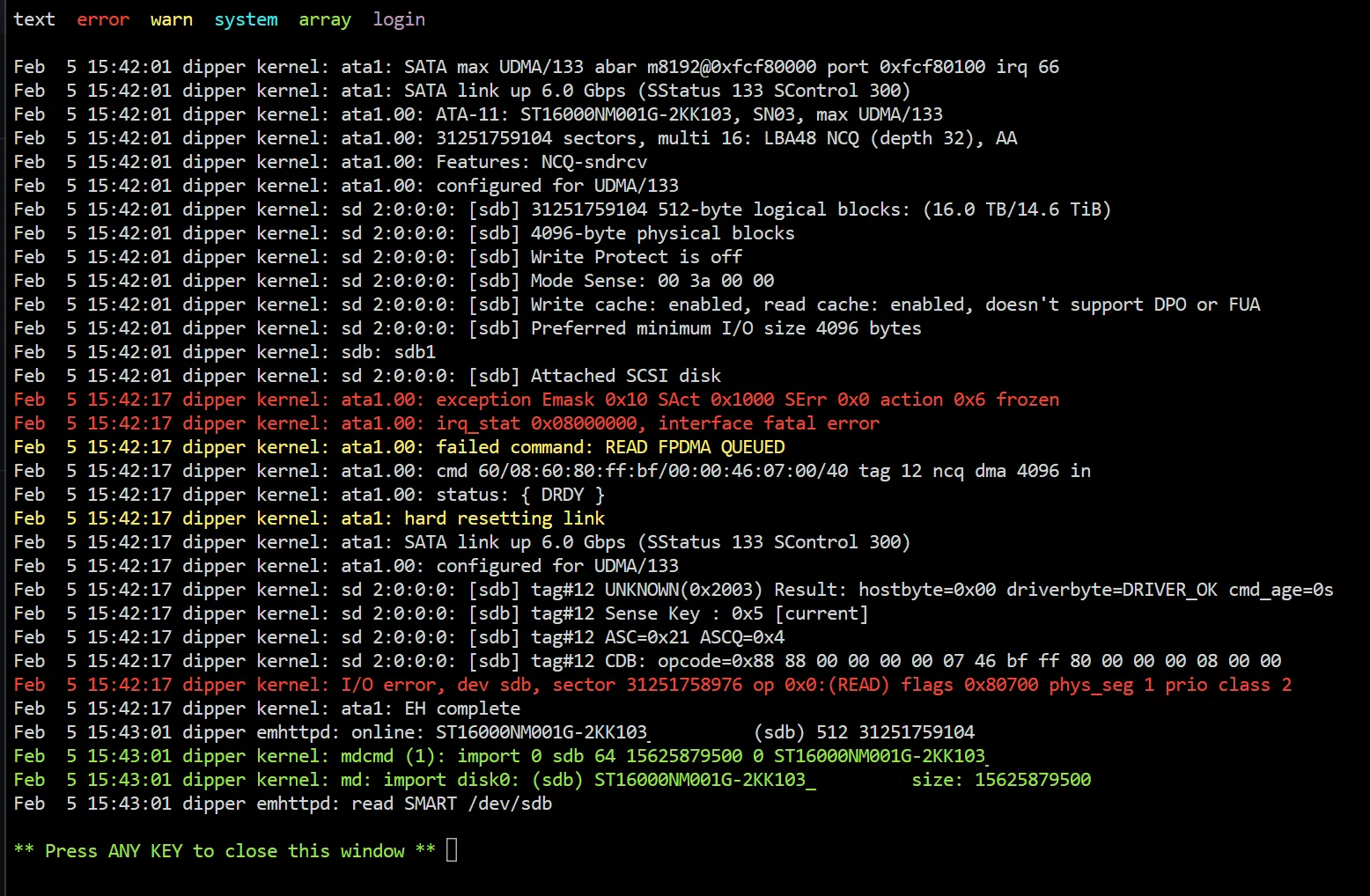
불행히도, 복구 시작 1분만에 새로운 드라이브들에서 똑같은 I/O 오류가 뜨기 시작했습니다. 심지어 한 디스크는 완전히 인식불가 상태로 사라져 버렸는데, 기존의 두 8 TB 디스크 중 하나와 유사한 방식으로 “고장”났죠. smartctl조차 행방불명된 디스크를 찾을 수 없었습니다:
Smartctl open device: /dev/sde failed: INQUIRY failed…그리고 나머지 디스크에 대해선 셀 수도 없이 많은 오류를 내뿜었는데, SMART 값들은 모두 정상 범위에 속했고 기준상 전부 괜찮아 보였죠:
Error 385 occurred at disk power-on lifetime: 20508 hours (854 days + 12 hours)
When the command that caused the error occurred, the device was active or idle.
After command completion occurred, registers were:
ER ST SC SN CL CH DH
-- -- -- -- -- -- --
04 61 02 00 00 00 a0 Device Fault; Error: ABRT
Commands leading to the command that caused the error were:
CR FR SC SN CL CH DH DC Powered_Up_Time Command/Feature_Name
-- -- -- -- -- -- -- -- ---------------- --------------------
ef 10 02 00 00 00 a0 08 01:08:16.785 SET FEATURES [Enable SATA feature]
ec 00 00 00 00 00 a0 08 01:08:16.785 IDENTIFY DEVICE
ef 03 46 00 00 00 a0 08 01:08:16.785 SET FEATURES [Set transfer mode]
ef 10 02 00 00 00 a0 08 01:08:16.784 SET FEATURES [Enable SATA feature]
ec 00 00 00 00 00 a0 08 01:08:16.783 IDENTIFY DEVICEdmesg에선 더 이해하기도 힘들고 무서운 오류들이 나타났습니다:
20:28:04 dipper kernel: ata2.00: configured for UDMA/133 (device error ignored)
20:28:04 dipper kernel: ata2: EH complete
20:28:04 dipper kernel: ata2.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x0
20:28:04 dipper kernel: ata2.00: irq_stat 0x40000001
20:28:04 dipper kernel: ata2.00: failed command: WRITE DMA EXT
20:28:04 dipper kernel: ata2.00: cmd 35/00:c8:e0:a3:05/00:01:00:00:00/e0 tag 19 dma 233472 out
20:28:04 dipper kernel: res 61/04:c8:e0:a3:05/00:01:00:00:00/e0 Emask 0x1 (device error)
20:28:04 dipper kernel: ata2.00: status: { DRDY DF ERR }
20:28:04 dipper kernel: ata2.00: error: { ABRT }
20:28:04 dipper kernel: ata2.00: failed to enable AA (error_mask=0x1)따라서 원인을 파악하려면 더 자세히 확인할 수 밖에 없죠. 새로운 디스크들이 기존 디스크들과 완전히 똑같은 방식으로 불량일 수도 없고, 완전히 새 디스크들이다 보니 더더욱 그럴 가능성이 희박하니까요.
깊숙하게 원인분석하기
일단 처음으로 시도해본 건 디스크들이 꼽혀 있는 드라이브 베이에 문제가 생겼는지 확인하려, 동생과 화상통화로 드라이브 베이 안 디스크 순서를 섞어봤습니다.
이상하게도, 디스크 배열을 바꾼 후, 문제들이 똑같은 디스크들에서 재발했습니다. 이 부분이 이해가 가지 않았는데, 만약 디스크들이 문제가 아니고 다른 부품이 문제라면, 어떻게 순서까지 변경한 후 동일한 디스크에서 오류가 재발할 수 있을까요?
전화 상 케이블들이 전부 다 제대로 연결되어 있는지 확인해달라고 했습니다. 이 부분도 역시 힘들었는데, 화질이 나쁜 영상통화로 선이 “제대로” 꼽혀있는지 확인하는건 꽤 어렵거든요. 동생이 연결 상태를 확인하면서, Jonsbo N1 벡플레인에 꼽혀들어가는 Molex 전선 중 하나가 완전히 꼽혀 있지 않았다고 하길래 아마도 전원 문제가 아닐까 기대해봤습니다. 문제가 디스크들을 따라다니는 이유는 먼저 떨어져나가는 디스크들이 불완전한 전원 공급에 가장 취약해서가 아닐까 했고, 새로 구매한 드라이브들이 전부 다 더 큰 용량을 가지고 있어 전원 공급이 더 원활해야 오류없이 동작할 듯 하여 가설에 힘이 실렸습니다.
아쉽게도, 완전한 문제 해결은 아니었습니다. 프리클리어 단계에선 문제없이 동작하는 듯하여, 프리클리어를 취소시킨 후 리빌딩 절차에 들어갔습니다. 하지만 리빌딩을 시작한지 불과 1분도 안되어 똑같은 문제가 재발했죠.
그래서 다른 원인을 찾아야 했습니다. 디스크부터, 수천킬로미터 떨어진 제 화면 사이에 의심해볼만한 부분들은 다음과 같았습니다:
- SATA 벡플레인
- SAS에서 SATA로 (1x4) 변환하는 확장 케이블 (SFF-8087)
- IT 모드로 플래싱되어 HBA로 동작하고 있는 LSI RAID 카드
- 메인보드
- PSU (전원공급장치)
- 전부 다 환각이었고 제가 미쳐가고 있을 가능성?
이때 집중이 쏠린 부분이 확장 케이블이었습니다.
역사는 반복한다?
UnRAID 포럼에서 도움을 요청하는 와중에, 2023년에 제가 작성한 글 하나를 보게 됩니다. UnRAID 업그레이드 이후 두 디스크가 동시다발적으로 죽어버린 경우였죠.
잠깐, 디스크 2개? 지금처럼?
2023년 6월쯤에 이 문제가 있었었는데, 당시에 베이징에 잠시 여행을 가서 서버 원인 분석을 제대로 할 수 없었죠. 다행히도, 2주 정도 이후에 한국에 돌아와 확인해보니 SAS에서 SATA로 변환하는 확장 케이블이 문제었습니다.
이게 왜 그렇냐면, Jonsbo N1 케이스는 미니ITX 케이스로 내부가 공간이 매우 비좁습니다. 너무 공간이 좁아 옆으로 튀어나온 SAS 케이블을 케이스 안에 우겨넣을려면 옆으로 접을 수 밖에 없죠. 우측으로 꺾여있는, 90도 케이블도 사용해봤지만, 벡플레인에 자리잡고 있는 SATA 연결부분까지 케이블을 보내려면 한번 접고 갈 수 밖에 없었습니다. 엎친데 덮친 격으로 SATA 쪽도 우측으로 꺾여 있어야 하는데, 안 그러면 서버 내부를 바깥 케이스 안으로 밀어넣을 때 갈려나갈 위험이 있고 만약 갈려나간다면 Jonsbo측에선 유상수리로 전환하거든요.
당시에는 케이블을 새로 구입해서 바꿨더니 아무런 문제 없이 디스크들이 전부 잘 동작했습니다. 지금까지는요.
”공급망 문제”
일단 한번에 HBA 카드와 확장 케이블을 교체하기로 결정했습니다. 만약 하나라도 불량이 아니었다면, 다시 배송을 받기 위해 기다리긴 싫었고, 가격도 그렇게 큰 차이가 없었습니다. 알리익스프레스에서 중고 카드 하나는 약 30불 정도밖에 안했고, 케이블은 거기에 조금만 더 얹어서 구매할 수 있죠.
하필이면, 서버 교체 부품을 구매하는 시기가 가장 끔찍한 지금이었다는게 문제였습니다. 중국의 새해 공휴일 때문에, 알리에서 여러 판매자들이 일주일 이상 휴가 기간에 들어가버렸죠. 부품이 창고에서 출고되서 중국에서 한국까지 선박으로 이동하면 2월 중순에서 말일까지 걸릴 텐데, 그럼 서버를 거의 한 달 가까이 사용할 수 없는 문제가 있었습니다.
그래서 조금 더 찾다가, ASMedia라는 회사에서 만든 칩셋이 달려 나온, PCIe에서 SATA로 변환을 해주는 카드를 발견하게 됩니다. 보니 HBA 카드랑 기능은 똑같아 보여서, 혹시 사용할 수 없는지 궁금해졌습니다.
예전에 어딘가에서 사용량이 증가하면 카드가 연결된 디스크들을 잃어버리는 일이 있다는 것을 기억했는데, 알고보니 이 종류의 카드가 아니라 SATA 포트 배분기 카드(port multiplier card)랑 헷갈렸다는 걸 알게 됐습니다. 마벨(Marvell)사 칩셋이 들어간 이런 카드들은 이 문제점이 있기 때문에 가급적 피해야 합니다. 일반적인 PCIe SATA 카드는 이런 문제가 있다는 경험담이나 정보를 찾을 수 없어 괜찮아 보였는데, 만약 카드가 ASM1166 칩셋 기반일 경우 정상적인 작동을 위해 간단한 펌웨어 업데이트가 필요한 걸 빼면 전부 다 괜찮아 보였습니다. 심지어 LSI 카드랑 비교해서 별 큰 차이가 없는데, LSI 카드를 IT 모드로 전환하기 위해선 어차피 펌웨어를 덮어씌워야 하기 때문이죠. 게다가 가격이 말도 안될 정도로 저렴했는데, 카드는 약 10불, 그리고 연결할 12개짜리 SATA 케이블 묶음을 2달러 주고 구입했습니다. 다 계산해 봐도 LSI 카드의 절반 가격보다 더 저렴하죠.
그래서 알리에서 ASM1066 칩셋 기반 카드를 주문했는데, 알리의 창고에서 출고되서 그런지 새해 공휴일도 무시하고 곧바로 출고되었습니다. (자본주의 이점.) 아쉽게도, 물류 검사를 하는 평택에 있던 세관은 그렇지 않아 2월 첫째주 쯤에야 카드를 받아볼 수 있었는데, LSI 카드를 배송받는 것보단 빨랐습니다.
카드가 도착했을 때, 예전 카드보다 더 서버에 잘 맞는다는 걸 발견했습니다. 예전 LSI 카드보다 공간도 덜 차지하고, 포트도 하드 디스크들이 있는 케이스 앞쪽으로 향하게 설계되어 있어, SATA 케이블을 구부릴 일도 없기에 케이블이 고장날 확률도 없애줬습니다.
그래서 모든 부품들을 다시 연결한 후, 서버 전원을 키고, 디스크들이 전부 감지된 후, 새로 복구 작업을 시작하고 다 마무리되었겠죠? 그렇겠죠?!
테세우스의 서버
만약 서버에 대한 거의 모든 걸 바꿨는데도… 이런 게 일어난다면:
말도 안되는 일이지만, 무슨 이유에선지 계속 오류가 발생했습니다. 이걸 다 했는데도요:
- 서버 하드 디스크들을 새 디스크들로 교체
- 서버 RAID 카드를 새로운 SATA 카드로 교체
- 카드와 백플레인 사이 케이블을 전부 새걸로 교체
- 백플레인에 연결된 하드 순서를 무작위로 바꿔 백플레인 제품 결함 없음을 검증
뭐가 문젠지 더 이상 생각조차 나질 않아서, UnRAID 포럼에다가 조언을 다시 구했습니다. ATA 오류들이 어디에서 오는지 파악조차 되지 않는 상황이었거든요. 포럼에서 관리자 @JorgeB가 답변을 달아줬는데, 아직도 연결 상태 — 특히 전원 쪽에 문제가 있다는 의견이었습니다.
불행히도 실험할 예비 PSU가 없었지만, 갑자기 방안이 하나 떠올라서 동생한테 전화를 걸었습니다. 연결되어 있는 Molex 커넥터를 한 칸씩 옆으로 이동해서 연결하면 혹시 연결 길이 때문에 문제가 해결될지 궁금했기 때문이죠. (여기에서 말하는 한 칸씩은, Molex 케이블에 병렬로 4개의 Molex 커넥터가 자리잡고 있는데, PSU에서 가장 멀리 떨어진 2개의 커넥터 대신 더 가까운 걸 사용하도록 다시 연결을 시도했습니다.)
이때 백플레인에 있는 연결 부위가 손이 잘 닫지 않는 부분에 있어, 동생이 연결을 해제하는데도 애를 먹었습니다. 연결 해제 과정이 오래 걸리면서, 혹시나 열 때문에 연결 부분이 녹아서 잘 빠지지 않을까 하는 생각도 들었죠. 만약 커넥터가 녹아버렸다면 연결 부위가 느슨해 접촉 불량도 생길 수 있고요. 아쉽게도 화질이 나쁜 영상 통화로는 확인을 할 수 없었고, 보내준 사진으로도 이 부분은 판독이 어려웠습니다.
 |
|---|
| ‘ChingLung’ 글귀가 새겨진 굵은 전선 밑에 4가닥으로 만들어진 Molex 케이블이 보이세요? |
다시 서버를 (수십번째) 조립을 마치고선, 전원이 켜진 후 프리클리어를 시작해서 입출력 문제가 사라졌는지 확인하기 시작했습니다.
첫고비 통과하기
UnRAID의 프리클리어 시스템은 다섯 단계로 구성되어 있는데, 그 중 세 단계만 디스크 전체를 건드리게 됩니다. 운이 없게도 (아니면 운좋게도?) 이번에 프리클리어하는 디스크들이 자그만치 16 TB나 되었죠.
기다리는 것도 조마조마했지만, 프리클리어를 취소하지 않고 끝까지 확인하도록 내버려 두었습니다. 만에 하나 디스크들을 복구하는 과정에서 다시 전원부 쪽에 숨어있던 문제가 발현된다면 더 골치아픈 상황이 될 수도 있으니까요. 그래서 그대로 프리클리어가 돌아가면서, 수시로 상태를 확인했습니다.
각 단계마다 약 20시간 정도가 소요되었는데, 16 TB짜리 디스크 상 모든 바이트를 읽거나 지우는데 20시간씩 걸린 셈입니다.
다행히도, 62시간이 지날 시점에 프리클리어가 성공적으로 마쳤습니다:
####################################################################################################
# Unraid Server Preclear of disk _____JFA #
# Cycle 1 of 1, partition start on sector 64. #
# #
# Step 1 of 5 - Pre-read verification: [20:44:44 @ 214 MB/s] SUCCESS #
# Step 2 of 5 - Zeroing the disk: [20:46:40 @ 213 MB/s] SUCCESS #
# Step 3 of 5 - Writing Unraid's Preclear signature: SUCCESS #
# Step 4 of 5 - Verifying Unraid's Preclear signature: SUCCESS #
# Step 5 of 5 - Post-Read verification: [20:44:42 @ 214 MB/s] SUCCESS #
# #
# #
# #
####################################################################################################
# Cycle elapsed time: 62:16:35 | Total elapsed time: 62:16:36 #
####################################################################################################
####################################################################################################
# S.M.A.R.T. Status (device type: default) #
# #
# ATTRIBUTE INITIAL CYCLE 1 STATUS #
# Reallocated_Sector_Ct 0 0 - #
# Power_On_Hours 3 65 Up 62 #
# Reported_Uncorrect 0 0 - #
# Airflow_Temperature_Cel 28 41 Up 13 #
# Current_Pending_Sector 0 0 - #
# Offline_Uncorrectable 0 0 - #
# UDMA_CRC_Error_Count 0 0 - #
# #
# #
####################################################################################################
# Report genereated on: February 08, 2025 at 13:00:38 #
####################################################################################################
--> ATTENTION: Please take a look into the SMART report above for drive health issues.
--> RESULT: Preclear Finished Successfully!그리고 조금 지난 후, 두 번째 16 TB 디스크 역시 프리클리어를 마쳐 희망이 살짝 생겼습니다:
####################################################################################################
# Unraid Server Preclear of disk _____DA5 #
# Cycle 1 of 1, partition start on sector 64. #
# #
# Step 1 of 5 - Pre-read verification: [21:27:40 @ 207 MB/s] SUCCESS #
# Step 2 of 5 - Zeroing the disk: [21:30:35 @ 206 MB/s] SUCCESS #
# Step 3 of 5 - Writing Unraid's Preclear signature: SUCCESS #
# Step 4 of 5 - Verifying Unraid's Preclear signature: SUCCESS #
# Step 5 of 5 - Post-Read verification: [21:27:42 @ 207 MB/s] SUCCESS #
# #
# #
# #
####################################################################################################
# Cycle elapsed time: 64:26:28 | Total elapsed time: 64:26:28 #
####################################################################################################
####################################################################################################
# S.M.A.R.T. Status (device type: default) #
# #
# ATTRIBUTE INITIAL CYCLE 1 STATUS #
# Reallocated_Sector_Ct 0 0 - #
# Power_On_Hours 3 67 Up 64 #
# Reported_Uncorrect 0 0 - #
# Airflow_Temperature_Cel 28 41 Up 13 #
# Current_Pending_Sector 0 0 - #
# Offline_Uncorrectable 0 0 - #
# UDMA_CRC_Error_Count 0 0 - #
# #
# #
####################################################################################################
# Report genereated on: February 08, 2025 at 15:10:38 #
####################################################################################################
--> ATTENTION: Please take a look into the SMART report above for drive health issues.
--> RESULT: Preclear Finished Successfully!복구 시작하기
복구를 시작하기 앞서, “손상된” 디스크들을 교체할 때 더 큰 용량의 디스크로 대체하는 바람에 복구 과정이 생각보다 조금 더 복잡했습니다.
일단 UnRAID에선 무결성 (parity) 디스크보다 더 큰 데이터 디스크를 구성하는 것을 허용하지 않기 때문입니다. 또한, 서버 상 사용 가능한 용량은 데이터 디스크들의 용량들을 전부 합친 것에 불과하기 때문에 두 8 TB 디스크들을 16 TB로 교체한다고 해서 당장 더 용량이 증가하는 것도 아니죠. 즉, 새로운 디스크들을 무결성 디스크로 구성해야만 하고, 이후에 만약 8 TB보다 더 큰 (물론, 무결성 디스크들 때문에 16 TB보단 작아야 하겠죠) 디스크로 데이터 디스크를 교체한다면, 그제서야 사용 가능한 용량이 증가하게 됩니다. 현재로선 이렇게 바꿈으로써 그냥 미래에 대비가 조금 더 잘 되었다고 보는게 맞습니다.
불행히도, 오류가 난 디스크 중 한 디스크는 데이터 디스크였는데, 아까 설명해드렸듯이 UnRAID에선 무결성 디스크보다 더 큰 데이터 디스크로 교체하는 것을 허용하지 않습니다. 첫 8 TB만 사용하게 하고, 나머지는 무결성 디스크들이 전부 업그레이드된 시점에 사용하게 해도 괜찮을 것 같은데 말이죠.
그나마 이러한 상황에 대비해서 “무결성 교체” (parity-swap) 절차가 있는데, 새 디스크들을 무결성 디스크들로 설정하고, 나머지 8 TB짜리 무결성 디스크를 데이터 디스크 슬롯에 옮겨넣으면 됩니다. 그럼 UnRAID에서 이전 디스크에서 새 디스크로 무결성 데이터를 복사하려는 것을 인식하고, 완료된 후 예전 무결성 디스크 위에 데이터 디스크의 내용을 복구하게 됩니다.
이렇게 디스크들을 슬롯에 구성한 후, 복사 버튼을 눌러 절차를 시작했습니다. 복사 도중에는 서버를 사용할 수 없지만, 절차 도중에 오류만 나지 않더라도 감사하는 마음이었습니다. 그래도 마지막으로 한번 놀래켜주고 싶었는지, 복구 도중에 이런 무시무시한 알림도 보내줬죠:
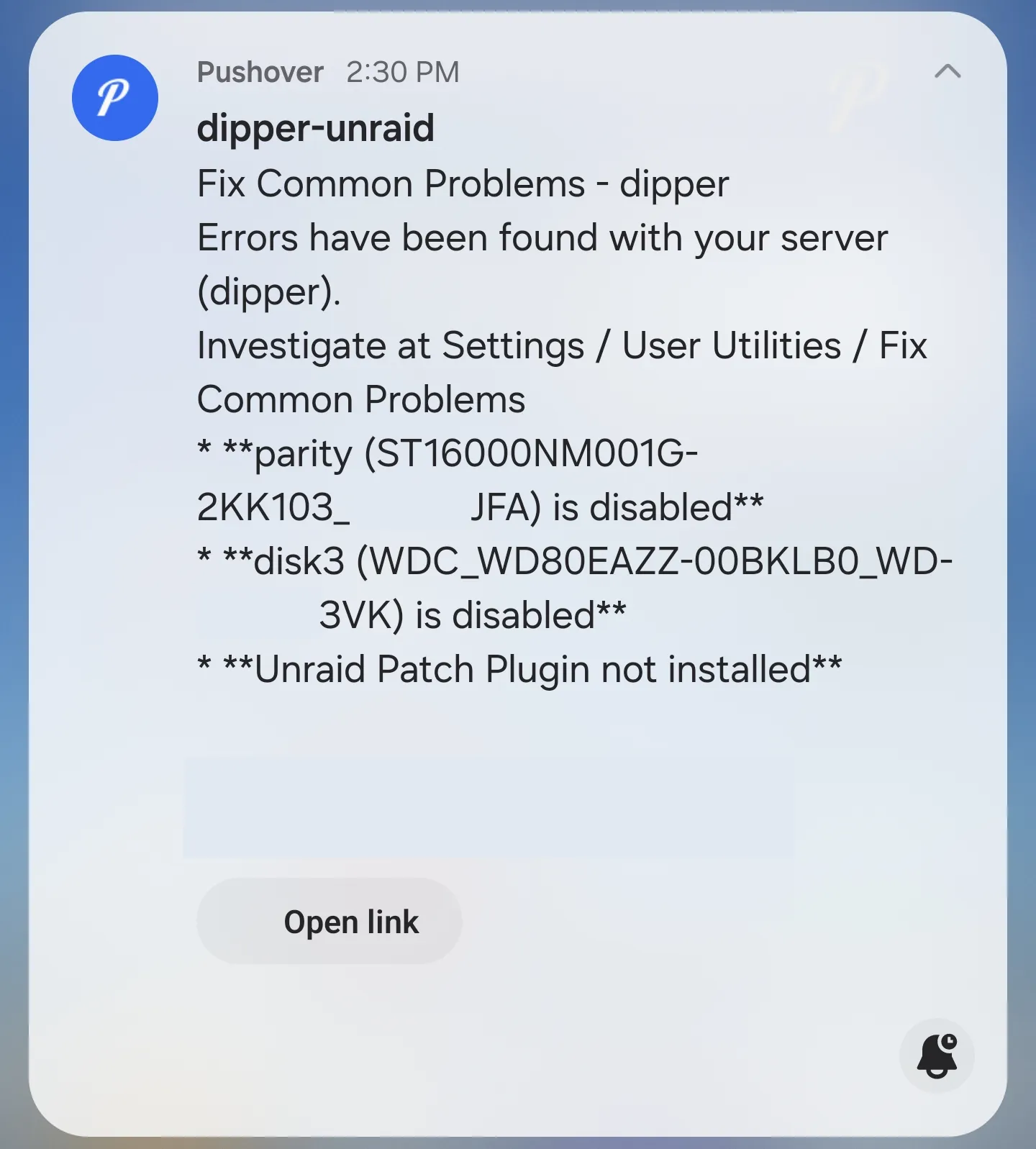
이 알림은 “흔한 문제 해결사” (“Fix Common Problems”) 플러그인이 서버가 이미 저하된 상태에서 돌아가고 있음을 경고해주려고 보내줬지만, “오류”라고 적힌 문구를 봤을 때 복구 도중에 디스크들이 전원 문제로 또다시 없어지거나 한 줄 알았습니다.
다행히도, 그런 문제는 일어나지 않았고, 몇 시간 후 무결성 교체 작업도 성공적으로 마무리되었습니다. 사실 프리클리어 단계들보다 더 오래 걸렸는데, 16 TB 디스크에 8 TB 디스크의 정보를 복사해올 때 아마도 8 TB짜리 디스크가 끝부분을 복사하면서 더 느려지기 때문에 그런 것 같습니다.
이후 데이터와 무결성 디스크들의 복구 절차를 시작했는데, 두 디스크를 한꺼번에 복구할 수 있게 되어 있었습니다. 이 부분이 가장 오래 걸렸는데, 약 27시간 (!) 정도 소요된 후 성공적으로 마쳤습니다:
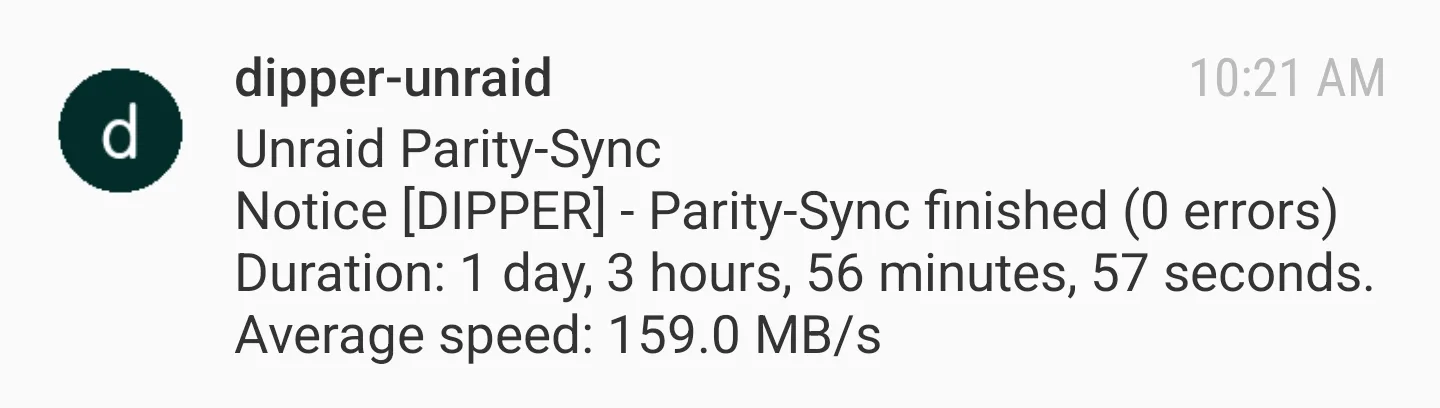
그렇게 28일동안 사용할 수 없었던 서버가 다시 원상복구되면서 상황이 종료되었습니다.
원인 분석
Molex 연결 부위를 건드린 후 처음에는 일시적으로 문제가 해결되다가 결국 완전히 복구가 완료되었음을 감안해서, 전원부 쪽에 집중하겠습니다.
일단, 전력량으로 확인했을때, 시스템 상 사양으로는 전원을 공급하기에 충분했습니다. PSU는 Lian Li사의 SP750 모델을 사용중인데, 사양표로 계산했을때 NAS에서 사용하는 전원은 최대 380 W 정도밖에 되지 않습니다. PSU가 공급할 수 있는 전력의 절반 정도니, 제한을 초과해서 생기는 문제는 결코 아니었습니다.
그러면 벡플레인까지 전원을 공급해주는 단일 케이블은 어떨까요? 시스템을 처음 조립했을 때, 이렇게 연결하는 방법 밖에 없었는데, Jonsbo 케이스의 벡플레인은 Molex 포트가 2개가 연결되는 것을 필요로 하지만, Lian Li사에서 제공하는 Molex 케이블은 분리되는 케이블 중 하나밖에 없거든요.
그럼 케이블이 고장날 때까지 용량을 초과해서 문제가 발생했을까요? 한번 계산해보겠습니다.
일단, 현재 NAS 안에 사용되고 있는 두 드라이브 모델의 사양표는 다음과 같습니다:
예전에도 설명했듯이, 16 TB 드라이브 2개, 그리고 8 TB 드라이브 3개를 돌리고 있습니다. 시게이트의 사양표에는 각 디스크 당 최대 전력량이 10 W라고 적혀 있는데, 디스크들이 처음 시작할 때 사용하는 전력은 나열하지 않습니다만, 10 W보단 당연히 높겠죠. WD는 12 V 레일에 최대 순간 전류량을 1.75 A로 표기하는데, 그럼 처음 시작할 때 사용하는 피크 전력은 약 21 W 정도가 됩니다. WD가 디스크들이 읽고 쓸 때 사용되는 평균 전력량을 6.2 W로 표기하는데, 시게이트의 전력량을 비교해봤을 때 동급으로 치부해본다면 시게이트의 처음 시작할 때 사용하는 피크 전력은 약 31 W 정도로 추정해 볼 수 있기에 그 숫자를 가지고 계산해보겠습니다.
그러면 디스크들이 처음 전원을 켰을 때 돌아가는 전력을 합산해보면 약 125 W 정도를 찍는데, 일반적으로 디스크들이 돌아가고 있을 땐 평균 전력 사용량이 약 38.6 W가 됩니다.
LTT 포럼글을 참조해보면, 단일 Molex 케이블은 12 V 레일에서 약 120 W의 전력을 공급해 줄 수 있습니다. 그러면 디스크들이 전부 시작할 때마다, 이 제한을 약 5 W 정도로 초과함을 알 수 있습니다. 물론, 이는 시게이트의 디스크들이 WD 디스크의 최대 순간 사용량과 똑같이 비례한다고 가정했을 경우에만 적용되기 때문에, 실제로는 그러지 않을 가능성이 있습니다. 그리고 일반적인 사용환경 아래에는, 케이블의 최대 전력량에 가까이 오지도 않죠.
그러면 어떻게 문제가 발생했는지 한번 가정해보겠습니다. 2022년 6월부터 줄곧 서버를 돌려왔기 때문에 거의 3년 동안 서버를 돌린 셈이 됩니다. 이 기간 동안, 아마도 케이블에 걸린 부하가 최대 전력량을 살짝 초과하면서, 전원 연결부가 과부하 아래의 열기에 살짝 녹으며 전원 연결핀들에 접촉 불량을 일으켰을 듯 합니다. 게다가 벡플레인 바로 위에 하드 디스크들이 돌아가면서 진동이 곧대로 전해져, 전원 케이블이 연결 포트에서 조금씩 느슨해지다가, 어느 시점에는 접촉 불량에서 초래된 불충분한 전압을 몇몇 하드 디스크들이 감당할 수 없어 서버에서 연결 해제돼 입출력 오류를 일으킨 듯 합니다.
Molex 플러그들을 한 열 이동해서 다시 꼽았을 때, 새 플러그들은 아직도 상태가 괜찮았기 때문에 벡플레인 포트와 접촉이 원할하게 이루어질 수 있어 문제가 해결된 듯 합니다.
이걸 조금 더 빨리 추론해서 새로운 부품들을 주문하고 기다리는 과정을 생략할 기회가 있었는데, 한번에 두 디스크가 동시다발적으로 서버에서 죽어버렸을 때 디스크가 문제가 아니었음을 직감했어야 했습니다. 제조일자가 동일하더라도, 제조 도중 편차 그리고 사용 패턴에 차이 때문에 똑같은 순간에 죽는 경우는 매우 드물거든요. 물론, 이건 다 겪어보고 나서야 알게 된 사실이니 미래에 참조하면 될 듯 합니다.
얻게 된 교훈 정리
물론, 만약 위에 적어둔 가정이 맞다면 이렇게 연결해 둔 것도 임시적인 해결책밖에 되지 않습니다. 케이블의 최대 전원 사양을 조금이라도 초과한다면 1-2년 정도만 되더라도 똑같은 문제가 발생할테니까요.
제대로 해결하기 위해서 추후에 단일 Molex 케이블 2개를 구매해서 PSU와 벡플레인 사이에 각각 연결할 계획입니다. 케이블에서 오는 전력 손실도 최소화하고 저항도 낮추기 위해 케이블 전선은 가장 굵은 전선으로 구성하면, 전력 손실에서 오는 열기도 최소화할 수 있죠.
일단 다행히도 홈서버가 복구가 완료되었고, 이 사태에서 데이터가 손실되지도 않았고 백업에서 복원할 필요도 없어 서버의 내구성은 계획한 대로 동작함을 확인할 수 있었습니다.
다음번에 이런 일이 발생할 경우 주문한 부품들이 오는데 기다리며 서버가 다운된 기간을 최소화하기 위해, 예비용 하드 디스크도 최소한 하나 구비해놓을 예정입니다. Jonsbo N1 케이스는 한번에 5개의 디스크만 설치할 수 있고 모든 베이를 사용중이기 때문에, 콜드 스페어(cold spare, 대체하는데 관리자 개입이 필요한 예비용 부품)로밖에 구성할 수 없지만, 중국에서 디스크들이 오는데 몇 주동안 기다리는 것보단 낫죠.
(참고로, 예비용 디스크를 1개 초과해서 구입하는 건 다음 이유들 때문에 별로 필요하지 않다고 생각합니다. 과거 추이를 바탕으로 디스크들은 계속 저렴해지고 있고, 아직도 2개 이상의 디스크들이 동시다발적으로 죽는 경우는 확률적으로 0에 수렴한다고 생각하거든요. 아이러니하게도 이 블로그 글을 작성하고 있긴 하지만, 이 경우에도 하드 디스크들은 아무런 문제가 없었고 처음부터 케이블 부분을 확인했다면 전혀 디스크들을 구매할 필요가 없었을테니까요.)
그럼 글을 마치면서, 만약 이상한 입출력 문제가 부품들을 교체했음에도 계속 발생하는 똑같은 상황을 겪고 있다면 한번 시스템의 전원부 쪽을 확인하고, 케이블들이 포트에 제대로 연결됐는지 확인하면서 문제해결에 이 글이 도움이 됐으면 합니다!